
Zusammenfassung Bachelor Thesis mit dem Thema:
Aufbau einer Data Warehouse-Architektur in einer Datenintegrationsanwendung anhand von „DataVirtuality“
10.08.18 von Benjamin Hör
In dieser Bachelor Thesis wurde überprüft, ob es möglich ist in der Datenintegrationsanwendung „DataVirtuality“ von der Data Virtuality GmbH eine Data Warehouse-Architektur zu implementieren. Als Data Warehouse-Architekturen wurden die Ansätze von William H. „Bill“ Inmon und Ralph Kimball herangezogen. Nach dieser Prüfung war auch eine Aussage darüber möglich, ob sich „DataVirtuality“ anbietet als Data Warehouse-Ersatz in einem Unternehmen zu fungieren oder „nur“ als Ergänzung angesehen werden kann, da ein Data Warehouse-Ersatz grundsätzlich immer Eigenschaften der Architekturvarianten von Inmon und Kimball ausweist.
Zu Beginn der Bachelor Thesis wurden die theoretischen Grundlagen vermittelt, um den Leser den Einstieg in das Themengebiet zu erleichtern. Das Hauptaugenmerk lag hierbei auf dem Data Warehouse-Umfeld.
Die theoretischen Grundlagen begannen mit den beiden Definitionen eines Data Warehouse von Inmon und Kimball. Im gleichen Zuge wurden auch die vier Kriterien eines Data Warehouse von Inmon genauer beleuchtet: die Themenorientierung, die Vereinheitlichung, der Zeitraumbezug und die nicht-Volatilität der Daten.
Anschließend wurden die verschiedenen Ebenen eines Data Warehouse erläutert. Hierfür wurde die Ebeneneinteilung von Sinz et al. herangezogen. Die folgende Grafik gibt einen Überblick über alle Ebenen.
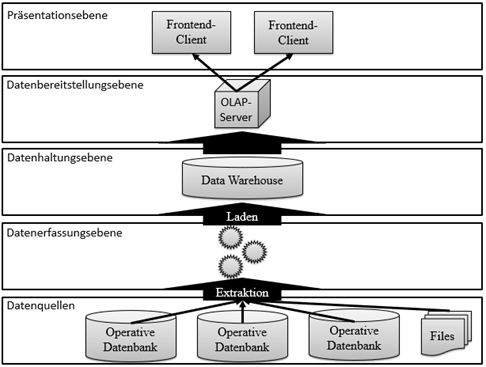
Die vorgelagerte Ebene der Datenquellen beinhaltet die Quellsysteme, die als Datenlieferanten für das Data Warehouse dienen. Die Datenerfassungsebene beinhaltet den ETL- oder den alternativen ELT-Prozess. Auf der Datenhaltungsebene kann zwischen einer zentralen und eine dezentralen Datenhaltung unterschieden werden, das heißt, ob die Daten an einem Ort oder verteilt vorliegen. Die Ebene der Datenerfassung dient als Schnittstelle zur Präsentationsebene und bereitet die Daten hierfür auf. Auf der Präsentationsebene werden die Daten für die Entscheidungsträger visualisiert.
Nachdem alle Ebenen eines Data Warehouse und deren Inhalte erläutert wurden, wurde das Data Mining näher beleuchtet. Data Mining stammt vom englischen „to mine“ und bedeutet so viel wie „schürfen nach“. Es wird hierbei versucht bisher unbekannte Zusammenhänge zwischen Daten zu finden.
Ein weiterer wichtiger Punkt war das Metadaten Management. Metadaten werden häufig als „Daten über Daten“ beschrieben und enthalten alle relevanten Informationen für die Entwicklung, den Betrieb und die Nutzung eines Data Warehouse. Beispiele für solche Metadaten wären Informationen über Datentypen und -formate.
Nach den allgemeinen Grundlagen über ein Data Warehouse wurden die beiden Architekturansätze von Inmon bzw. Kimball erläutert, zum einen die Corparate Information Factory von Inmon und zum anderen die Data Mart-Busarchitektur von Kimball.
Der größte Unterscheid zwischen den beiden Ansätzen ist die Datenmodellierung. Während Inmon ein normalisiertes Datenmodell favorisiert, ist für Kimball ein mehrdimensionales Datenmodell im Vorteil. Eine Gemeinsamkeit ist ein zentrales Repository, das die Daten bereithält.
Nach den theoretischen Grundlagen wurde die Methodik der Thesis erläutert, die in diesem Falle eine Anlehnung an die Nutzwertanalyse war. Es gab jedoch keine Auswahl an Alternativen, sondern es wurde lediglich der Erfüllungsgrad der einzelnen aufgestellten Kriterien, die an die Ansätze von Inmon und Kimball angelehnt waren und im gleichen Zuge in einem Katalog zusammengefasst wurden, gemessen. Die einzelnen Kriterien wurden nach ihrer Wichtigkeit gewichtet und es wurde ein Endergebnis ermittelt, indem der Erfüllungsgrad mit der Gewichtung multipliziert wurde und aus allen Produkten eine Summe gebildet wurde. Anhand dieser Summe war es möglich eine Aussage darüber zu treffen, inwieweit es möglich ist eine Data Warehouse-Architektur in „DataVirtuality“ aufzubauen. Aus dieser Aussage war es auch möglich abzuleiten, ob „DataVirtuality“ eine Ersatz oder eine Ergänzung zu einem Data Warehouse darstellt.
Die Kriterien, die im Zuge der Thesis untersucht wurden, waren: Autarkie der Softwarelösung als Data Warehouse-Ersatz, Konnektivität der Softwarelösung, Historisierbarkeit der Daten, Skalierbarkeit und Erweiterbarkeit, Automatisierbarkeit von Prozessen, Methoden zum Harmonisieren der Daten, Methoden zum Modellieren der Daten, Verfügbarkeit, Bedienbarkeit und Methoden zur Datensicherung und Wiederherstellbarkeit.
Die Auswertung der Ergebnisse hat gezeigt, dass es nur bedingt möglich ist eine Data Warehouse-Architektur in „DataVirtuality“ zu errichten. Der Erfüllungsgrad der Kriterien mit der größten Wichtigkeit war sehr gering. Kriterien mit geringerer Wichtigkeit wurden dagegen besser bewertet. „DataVirtuality“ ist dementsprechend nicht als Data Warehouse-Ersatz anzusehen. Als Ergänzung eignet es sich jedoch, da die Anwendung auch ihre Vorteile bietet.